
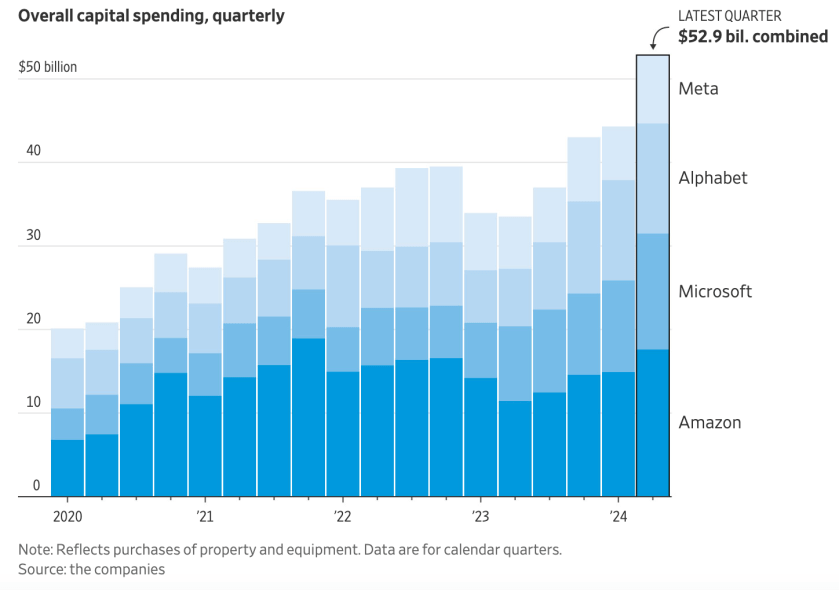
No one said making money with Generative AI was going to be easy, but with costs skyrocketing even the biggest, most solvent and strategic investors are growing uncertain about the financial prospects of LLMs.
It raises the question not just when it will be possible for them to turn a profit on their investments, but is it even possible. Right now it’s unclear how IP rights will play a part, except possibly in content training and hardware, or if they will. Specialty chipmaker Nvidia, with a $3.5 trillion market cap is not complaining.
“The risk of underinvesting is dramatically greater than the risk of overinvesting,” Sundar Pichai, chief executive of Google parent Alphabet, said on an earnings call in July.
Right now it’s unclear how IP rights will play a part, except possibly in content training, or if they will
Venture capitalists, who are betting that at least some of their many investments in AI will payoff, have backed off of their peak spending of about $130B in 2021 to about half of that through the first eight months of 2024.
Nvidia Shows No Signs of Weakening
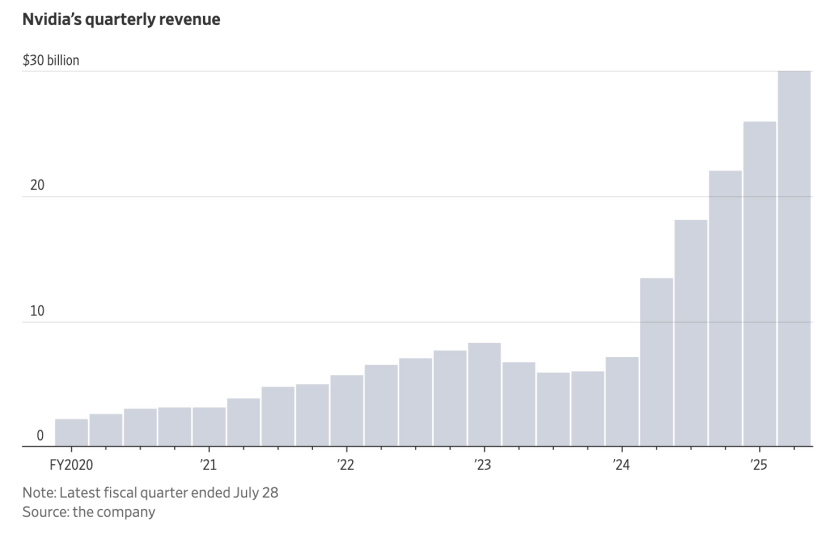
One beneficiary of all of the spending is GPU chipmaker Nvidia, whose fourth quarter revenue will climb to $23B in 2024 and is projected to reach $30B in early 2025. Nvidia’s 4Q revenue in 2023 was $6B.
Many experts believe we will eventually all rely on a variety of AIs—some from closed providers like OpenAI and Google, others from the kind of open-source challengers Meta is investing in and Alphabet has been experimenting with. The nature of that mix will determine whether it was worth it for companies to spend tens of billions of dollars building advanced AIs.
Hardware/chips, training (which requires licenses with publishers and other copyright owners), server and energy costs are prohibitive for all but the biggest players – and even they are feeling the weight
Some businesses are finding that small language models tailored for very specific tasks can be more effective and efficient than large language models (LLMs), reports Salesforce’s 360 Blog. Small models are less expensive to train and maintain, and often outperform the kitchen-sink approach of their gigantic multipurpose counterparts.
Smaller, More Focused Datasets
A small language model is a machine-learning algorithm that’s been trained on a dataset much smaller, more specific, and, often, of higher quality than an LLM’s. It has far fewer parameters (the configurations the algorithm learns from data during training) and a simpler architecture. Like LLMs, the advanced AI systems trained on vast amounts of data, small language models can understand and generate human-sounding text.
Hardware/advanced chips, training (which requires signed licenses with multiple publishers and other copyright owners), server and energy costs are prohibitive for all but the very biggest players – and even they are feeling the weight of the challenge. In many cases, general-purpose LLMs with tens of millions of parameters may be overkill for business users who need help with specific tasks.
Is it possible that the business model the biggest players aspire to is less about subscriptions than prompt and response ownership?
Investors are not convinced the biggest tech players will not succeed, but they are watching them carefully.
Bromance Fraying?
OpenAI CEO Sam Altman once called his company’s partnership with Microsoft “the best bromance in tech,” but ties between the companies have started to fray, writes The New York Times.
Financial pressure on OpenAI, concern about its stability and disagreements between employees of the two companies have strained their five-year partnership, according to interviews with 19 people familiar with the relationship between the companies.
Image source: Dow Jones
